[ToDoList] Dockerising the App
So we've covered all the basic Ruby and Rails magic that has allowed us to build a basic web application, as well as made it look like a passably professional piece of work.
This certainly deserves another whoop of celebration if you're not already whooped out.
However at this point, you might already have run into problems with the joys Ruby / Rails / Bundler / Node versions, particularly if you have been working on different systems.
It is also entirely possible that you're a bit sick of the VM or online IDE you are using to build the app, and you are hoping for a better solution.
The solution to both of these is the mighty Docker (other container frameworks are available).
You may have already heard of Docker, being a tool that essentially revolutionised app development and deployment by using a funky little addition to the Linux kernel: namespaces. Think of these almost as Virtual Machines (though much, much cooler and resource-friendly) that allow isolated instances of other environments to run simultaneously with your primary one.
Docker contains a repository of images (think snapshots of operating systems) from which to base custom images from in order to provide containers that will run
exactly the same no matter which system you are running it on for a fraction of the computing resource and space of a virtual machine, addressing the two issues presented above!
As an extra flex, Docker is built with Google's Go language, and is a huge part of the reason that Windows has an Ubuntu shell available on it.
Obviously it goes without saying that if you were brave enough to build the app in Docker from the start using docker-compose,
you can probably largely skip this step. Still, you might learn something.
So before we can use this incredible piece of software, we need to get it onto our host machine. This won't be the VM or online IDE you have probably been using up until now,
but your primary operating system. This guide will, of course, focus on installing Docker to an Ubuntu/Linux system (which can be used with Mac as well).
Windows installation will obviously be a bit different and is covered quite extensively by Docker in their docs.
So, let's the required packages:
$ sudo apt install docker.io docker-buildxWell, not quite. Because Docker interacts with some very high-level stuff, it will automatically require
root access to run every time (i.e. sudo).
Luckily, we can get around this and wield the power of Docker from our normal user by creating a docker group and adding ourselves to it:
$ sudo groupadd docker
$ sudo usermod -aG docker $USER
$ newgrp docker ## run this in each new terminal until you reboot
As mentioned previously, Docker works with images to clone instances of operating systems onto containers where they are run in their own isolated namespaces.
This means that, in order to work with Docker, we will need an image of our app running in an operating system and clone this to a container where it can run in peace.
If this sounds scary, that's good. It's incredible stuff we're working with here. But don't let that fear put you off, because Docker has made this literally too easy.
The configuration for our image and container is specified in a DockerFile that is specific to the application we are wanting to Dockerise.
This does a large number of jobs using a number of key-value combinations explained below:
-
Source Image
-
The
FROMkey denotes which source image Docker will use to build our new image from - in this instance, we will use arubysource image. -
It is hugely advised that a version is specified with the selected image - in most cases, this should be the same version of Ruby that is specified at the top of our
Gemfile:
Not doing this so will default to the$ cat Gemfile | head -n 5 source 'https://rubygems.org' git_source(:github) { |repo| "https://github.com/#{repo}.git" } ruby '3.3.0'latestimage every time our app's image is rebuilt, which will cause issues when this version passes the version in yourGemfile. - If you really want to use the latest available version of Ruby from Docker, but cannot install this on your local machine, see the guide for setting up New Rails Apps with Docker Compose which outlines how to create the app purely within Docker containers (meaning your are not limited to the highest version of Ruby available to your local machine's OS). It is hugely recommended that you read this section and its subsection before this, though.
-
The
-
Setup Instructions
EachRUNvalue will be run in the shell of the container that is creating the image, which allows us to run various commands including:-
Updating the
aptpackage cache and installing the required dependencies from it (node.js package manager and postgres client). -
Installing yarn and a recent, stable version of node.js with
npmthat we installed withapt.
(Note that again, we are specifying a specific numbered version of node and not just the a labelled version). -
Running
bundlerto pull our gem dependencies for our app. - Manipulating the filesystem and permissions so as to avoid issues later.
- Creating our database and running the migrations we have generated.
-
Updating the
-
Directory Population
-
Each
ADDvalue will copy the specified file or directory to the passed location on the image.
In this instance, we will be copying the entire application directory (.) over to theto_do_listdirectory on the image. -
WORKDIRdenotes the location that Docker will run the subsequent actions from, until a newWORKDIRis declared.
-
Each
-
Port Access
Port numbers passed toEXPOSEwill be made available from the container by Docker - in this case we want to expose port3000as this is where the Rails development server runs. -
Container Function
An array making up parts of the command we want the container to run when it spins up are specified with theCMDkey - here we are just running the rails server with a binding to the required internal network address:bundle exec rails s -b 0.0.0.0.
Using what we've learned above, we can build our Dockerfile for the image and container we want to create, and put in the app's root directory:
FROM ruby:2.7.0 ## matching ruby version in our Gemfile
RUN apt update -qq \ ## update package cache
&& apt install -y npm postgresql-client ## install packages not included in ruby image
RUN npm install --global yarn n ## install yarn and node
RUN n 16.4.0 ## install stable node.js
ADD . /to_do_list ## copy app to image
WORKDIR /to_do_list ## run all subsequent actions from this dir
RUN bundle install ## install gems
RUN mkdir tmp/db && chmod -R 777 tmp/db ## avoid issues later with database permissions
RUN bundle exec rails db:create ## create the database
RUN bundle exec rails db:migrate ## run migrations
EXPOSE 3000 ## make port 3000 accessible to us
CMD ["bundle", "exec", "rails", "s", "-b", "0.0.0.0"] ## run the rails server when the container is runnodejs sees a much more rapid release schedule than ruby,
the version we are able to use is limited by the environment that our container exists in (e.g. operating system).
There are usually ways around this, such as using the image of the utility that receives more updates and installing the other tools onto it.
However, in this example, nodejs's own package manager (npm) makes upgrading extremely easy!
The final thing to do before we build our image is to set up a .dockerignore containing, you guessed it, the files we want Docker to ignore.
Luckily, the files we want Docker to ignore is almost identical to what we want git to ignore, so we can start by just copying the .gitignore file:
$ cp .gitignore .dockerignore/.git*
/Dockerfile*
/docker-compose*
/.dockerignore
/tmp/db
/config/database.yml.*
With our basic config set up, we can now set about creating an image of our application, based on the ruby:2.7.0 image we specified in the Dockerfile.
All we need to do is run the command and specify the current directory (.), and maybe give it a nice repository name, too:
$ docker build -t to_do_list .Dockerfile (in order), including pulling the source image down from DockerHub if we don't already have it,
and save it to an image. If all goes well, we can see our lovely new image afterwards with:
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
to_do_list latest f0c2ad6a602a 2 minutes ago 1.5GB
ruby 3.3 dddf6b6befbf 2 weeks ago 989MB
With all this done, we can now create a container from our image using an almost equally easy command that names the container and points it at an image.
The only difference here is that we need to bind the port exposed by Docker (3000) to an available one on our host machine.
This can easily be the same port but, just for fun, we'll set it slightly different:
$ docker run --name to_do_list_web -p 8008:3000 to_do_listnewgrp docker if you haven't rebooted yet), we can check it using Docker's own ps command:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8d12ba454808 to_do_list "bundle exec rails s…" 1 minute ago Up 1 second 0.0.0.0:8008->3000/tcp, :::8008->3000/tcp to_do_list_web
If we wanted to check that the container has all of the goodness we need it to, or indeed to check it doesn't have anything too incriminating in there, we can even access the bash
shell that is running on the container using Docker's exec functionality, passing it the container name / ID and the command we want to run:
$ docker exec -it to_do_list_web /bin/bash
root@8d12ba454808:/todoapp-test#WORKDIR we specified in the Dockerfile.
If we now navigate to http://localhost:8008 in our browser, we can see our beautiful app presents itself!
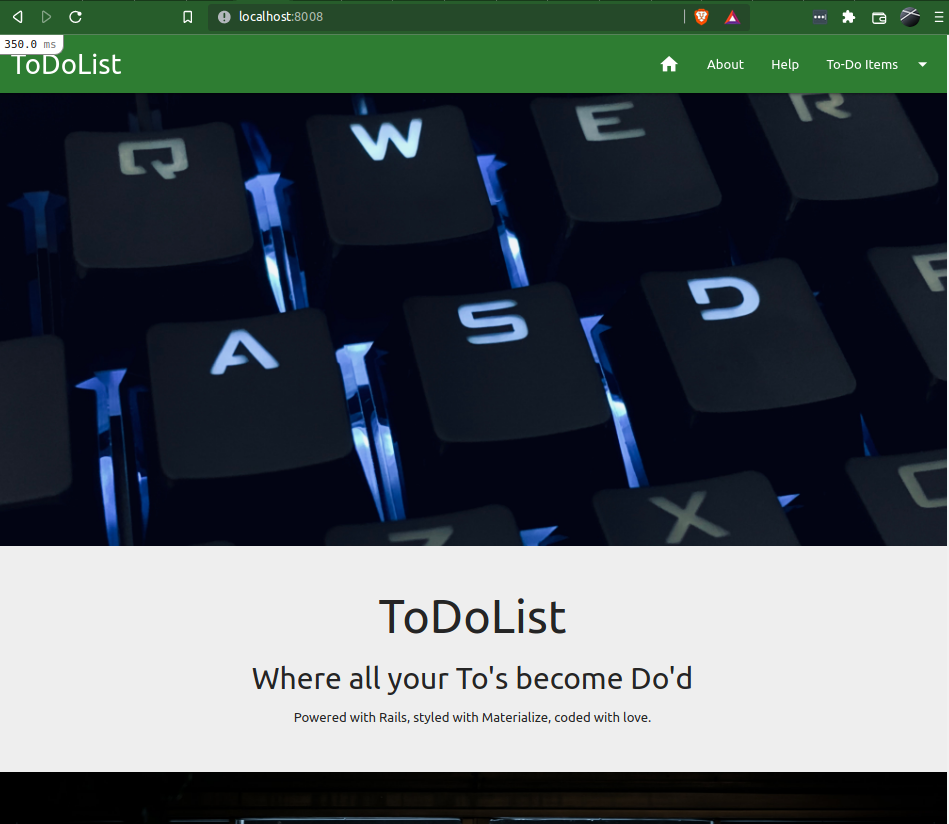
When we're ready, hitting Ctrl + c in the terminal running our container will kill it.
If we then want to start the container again, this is done differently to how we built the container - if you don't remember the name or ID of the container we can find it with:
$ docker ps -a ## a for all, meaning offline
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8d12ba454808 to_do_list "bundle exec rails s…" 1 hour ago Exited (1) 30 minutes ago 0.0.0.0:8008->3000/tcp, :::8008->3000/tcp to_do_list_webstart command to start it up again in the background:
$ docker start to_do_list_webBecause this started in the background, you might wonder how we can stop this container - Docker has your back:
$ docker stop to_do_list_webNow, the caveat to all of this. Obviously, because Docker is building each container from an image, every time we make a code change we need to rebuild the image and the container. This can lead to some pretty messy lists of Docker images, especially if you're tracking a bug and rebuilding the image several times an hour...... (not me, I'm angry on a friend's behalf..).
The simplest way around this, and preferable to those with limited storage space, is to delete your container and image before you build the next version:
$ docker rm to_do_list_web
to_do_list_web
$ docker image rm to_do_list
Deleted: sha256:d01c433a3996e28fa9c6c8596071c910e66094743db5dc01a679883d455159d3
Deleted: sha256:c0ad1e756f03cff7db1efc80db32345b54d60cd0ca47762b3d11256927c1ed88
Deleted: sha256:334dcc769f9e28821aa7faffa5025bcda23f96cda3dfad4b7a4c40f0616d115fWhat we can do instead is use Docker's tag system to keep a sensible number of previous image versions on disk, and differentiate between them using whatever indicator you see fit, e.g.
-
A simple numbered versioning system, tried and tested:
[0.0.1, 0.0.2, 0.0.3].
This has an additional advantage of using different positions to indicate major, minor and patch versions, e.g.[0.1.1, 0.1.2]patch versions could indicate small changes to stamp out bugs.[0.2.0, 0.3.0]minor versions can be used when the bug or issue is found and resolved.[1.0.0, 2.0.0]major versions show when you have a fully tested version with significant differences to the previous major version.
- Debian uses Toy Story characters in a seemingly random order:
[jessie, buster, bullseye]. - Ubuntu uses an adjective-animal tag in alphabetical order:
[Bionic Beaver, Cosmic Cuttlefish, Disco Dingo]. - In a project with my stepson, he elected to use Pokemon in Pokedex order:
[Gengar, Onix, Drowzee].
build command:
$ docker build -t to_do_list:0.0.2 .
Sending build context to Docker daemon 140.4MB
Step 1/13 : FROM ruby:2.7.0
---> ea1d77821a3c
Step 2/13 : RUN apt-get update -qq && apt-get install -y npm postgresql-client
---> Using cache
---> 1726273dbbe4
Step 3/13 : RUN npm install --global yarn n
---> Using cache
---> 02063daba50f
Step 4/13 : RUN n 16.4.0
---> Using cache
...When this has finished, we can check our list of images and see our new version!
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
to_do_list 0.0.2 2aca8d3bab54 7 seconds ago 1.53GB
to_do_list latest f0c2ad6a602a 38 minutes ago 1.53GB
ruby 3.3 dddf6b6befbf 2 weeks ago 989MBlatest tag to our new version - this is deliberately so, as Docker doesn't know if you want this
to be your latest stable version yet!
If we're happy with our new version, we can apply this tag manually with:
$ docker image tag to_do_list:0.0.2 to_do_list:latest
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
to_do_list 0.0.2 2aca8d3bab54 1 minute ago 1.53GB
to_do_list latest 2aca8d3bab54 1 minute ago 1.53GB
<none> <none> f0c2ad6a602a 39 minutes ago 1.53GB
ruby 3.3 dddf6b6befbf 2 weeks ago 989MBlatest tag away.
We can fix this in a similar fashion by pointing the image's ID to the tag we want to give it:
$ docker image tag f0c2ad6a602a to_do_list:0.0.1
$ docker image list
REPOSITORY TAG IMAGE ID CREATED SIZE
to_do_list 0.0.2 2aca8d3bab54 2 minutes ago 1.53GB
to_do_list latest 2aca8d3bab54 2 minutes ago 1.53GB
to_do_list 0.0.1 f0c2ad6a602a 40 minutes ago 1.53GB
ruby 3.3 dddf6b6befbf 2 weeks ago 989MB
Docker doesn't have quite the helpful tooling for containers as it does for images, and additionally doesn't allow multiple containers to share the same name.
There are multiple approaches around this, such as container labels or simply adding the version to the name container name (i.e. to_do_list_web_0.0.2).
However, personally, I find removing names altogether (or rather, using the default ones) a perfect acceptable way of using Docker containers!
$ docker run -p 8008:3000 to_do_list:0.0.2$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
990cf24f6ca9 to_do_list:0.0.2 "bundle exec rails s…" 1 minute ago Exited (1) 20 seconds ago 0.0.0.0:8008->3000/tcp, :::8008->3000/tcp tasty_bill
8d12ba454808 to_do_list:0.0.1 "bundle exec rails s…" 1 hour ago Exited (1) 1 hour ago 0.0.0.0:8008->3000/tcp, :::8008->3000/tcp to_do_list_web
In all, Docker is an extremely cool bit of kit. Celebration of this should require zero effort though, if you need some pointers, why not push what we've done up to GitHub?
$ git checkout -b dockerise
$ git add -A
$ git commit -m "Docker config for app"
$ git push origin dockeriseWell, wouldn't you know it, Docker thought of that, too. The subsection linked below will show you how to use Docker Compose to alleviate both of these issues and provide an almost seamless development experience, combining all the benefits of Docker with all the convenience of working in your local filesystem!
| < [ToDoList] Materialize V: Other Pages | | | [ToDoList] Docker Compose > |
| Back | ||

Comments
Post a Comment